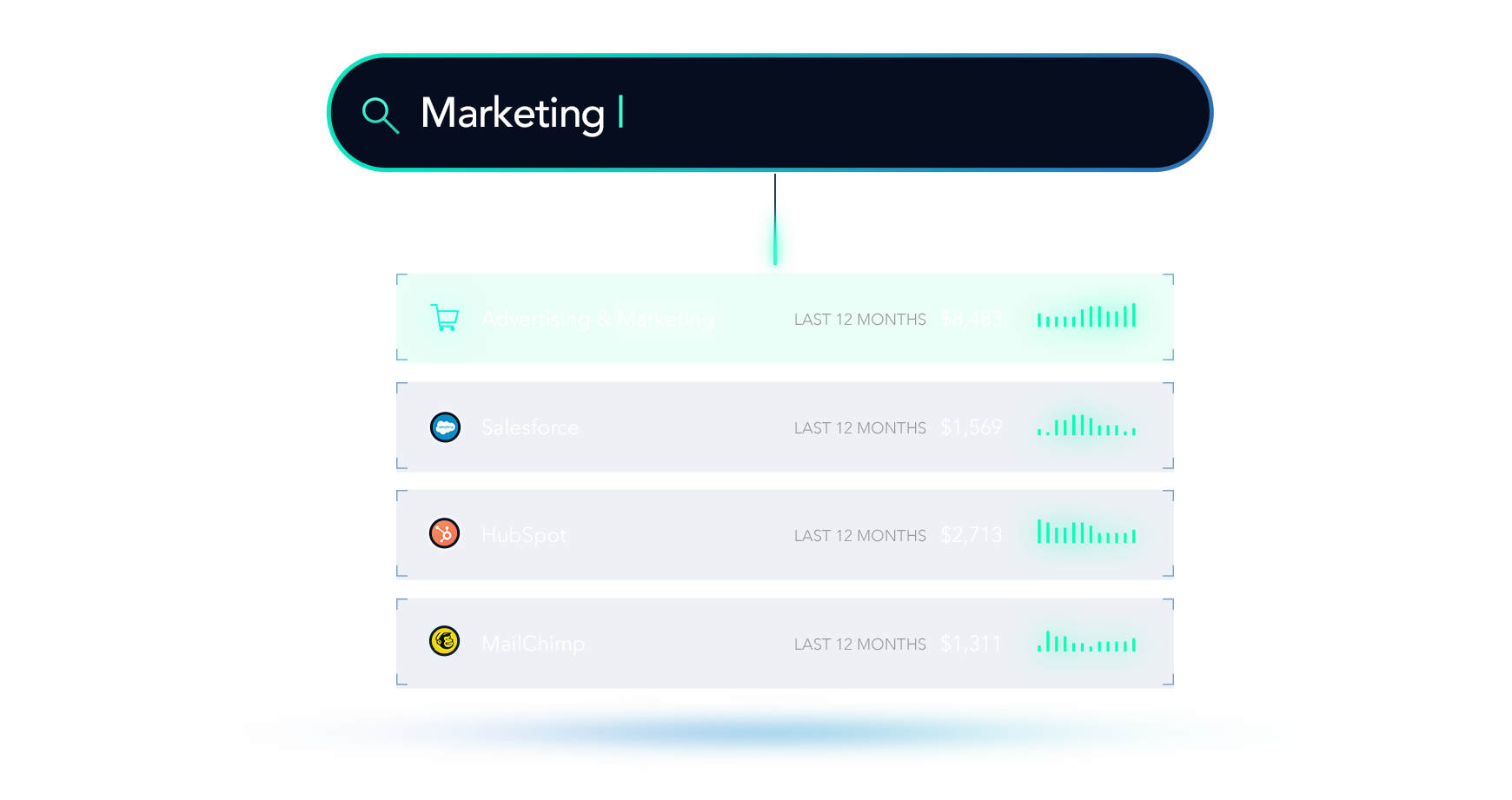
Architecting Digits Search: Real-time Transaction Indexing With Bleve
We recently launched Digits Search, which brings fast, beautiful, full-depth search to business financial data. We’ve received a ton of great customer feedback, but one question just keeps coming up…
How did you build this!?
Well, let’s break down how Digits Search puts your finances at your fingertips.
Digits Architecture
First, some quick background on Digits:
Digits links with your business’ accounting software and your financial institutions to build, and continually maintain, a living model of your business with the most up-to-date data. Once linked, we ingest all of that financial data in raw form, a collection that we call “facts”.
We then use machine learning and data processing to normalize all of that overlapping, unstructured data. We perform a significant number of calculations to fill holes in the picture, such as predicting how your latest transactions will be categorized, detecting and predicting recurring activity, etc.
The end result of all this work is a “view”, which is then efficiently loaded into Google Cloud Spanner as well as encrypted and archived in Google Cloud Storage for secondary processing.
Each view we produce is a complete, standalone picture of your company’s entire financial history.
Views are served by our serving layer, which is composed of a number of services communicating over TLS-encrypted GRPC APIs, written in Go and hosted in GKE. Our serving layer aims to optimize for efficiency, security, and reliability.